CS 461 Homework 2
Due: Midnight, January 29, 2009
Please your answers to these questions in <yourlastname>-hw2.txt (or
PDF).
Part 1: Decision Trees (40 points)
Given this data set (two classes: Dog and Cat) and the partially built decision tree at right, calculate the impurity of nodes A though D using misclassification error (I = 1 - maxi (pi) where i ranges over all possible classes and pi is the probability of class i over just the items at the current node). Show your work, using 3 significant digits. (10 points)
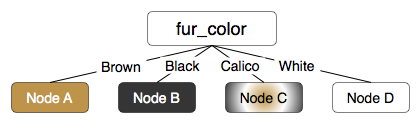
weight (lbs) number_of_legs fur_color Class 33 4 brown Dog 9 4 black Cat 41 4 brown Dog 12 4 calico Cat 20 4 black Dog 7 4 brown Cat 25 4 brown Dog 22 4 white Dog 10 4 brown Dog 28 3 black Dog 19 4 brown Dog 17 4 white Cat 9 4 brown Cat Now calculate impurity for nodes A through D using entropy (eqn. 9.3). Show your work, using 3 significant digits. Treat any "log2(0)" values as being equal to 0.0. (10 points)
Now consider splitting node A using the weight feature. Select a reasonable value for theta to split. Calculate the impurity (using entropy) that would be achieved if we split on this feature (eqn. 9.8). Show your work. Treat any "log2(0)" values as being equal to 0.0. (6 points)
Given the decision tree shown in question 1 (no split on weight), show what class ("cat" or "dog") it would assign to each of the items in the following test set. What is the decision tree's error rate? (4 points)
weight (lbs) number_of_legs fur_color Class 15 4 black Dog 21 4 calico Cat 11 4 brown Cat 84 4 brown Dog 7 4 brown Cat Turn this tree into a set of three classification rules (one for each possible class): (6 points)
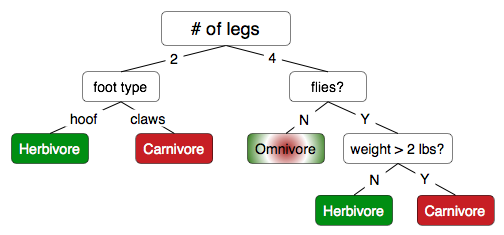
What is the difference between pre-pruning and post-pruning a decision tree? (4 points)
Part 2: Evaluation (10 points)
Why do we separate our data into training and test sets? That is, why not just have one data set, train the model, and then report its error rate on that data set? (4 points)
What is the difference between recall and precision? (3 points)
Using McNemar's test, determine whether algorithm 1 and algorithm 2 have significantly different performance, at a significance level of 0.05 (95% confidence), given this contingency table: (3 points)
43 52 31 251
Part 3: Support Vector Machines (30 points)
Why does a quadratic model generally require more training data than a linear model? (3 points)
In gradient descent, what is the gradient and why do we want to descend it? (3 points)
How can an SVM be applied to data that is not linearly separable? (4 points)
Why do we seek to maximize the margin? (3 points)
What are three common nonlinear kernel functions? (3 points)
In the context of an SVM, what is the C parameter? (2 points)
Given the following training data, the SMO algorithm produced the linear SVM weight vector shown.
Is it a waltz? Tempo (bpm) Duration (sec) Year of composition Class (y_i) x_1 33 185 1897 +1 x_2 42 147 1945 -1 x_3 67 102 1883 -1 x_4 30 193 1902 +1 Weight vector:
Tempo (bpm) Duration (sec) Year of composition -0.0071 0.0247 -0.0208 with a bias value of 36.0399.
Show how to classify a new item, x. (6 points)
New item x Tempo (bpm) Duration (sec) Year of composition Class (y_i) 35 165 1921 ? Assume you have a problem with four classes. You want to build a single classifier that will output which class a new item is, but all you have is code for a binary SVM. How can you use this code to create a multiclass SVM classifier? (6 points)
Part 4: Weka (20 points)
(1 point) Run Weka and select "Explorer." Use the "Open file..." button to load vote.arff. (Consult the Explorer Guide if you get stuck.) Set the class attribute to "class" and browse the class distribution plots for each attribute. Which attributes (if any) provide a good separation between the two classes (Democrat and Republican)?
(4 points) Switch to the "Classify" tab and select "IBk" (click "Choose", then "Lazy", then "IBk"). This is the k-nearest neighbors algorithm. By default, k is set to 1. You can click on the "IBk -K 1 -W 0" line to change the K value (type in the "KNN" field). Under "Test options", select "Cross-validation" and set "Folds" to 10. Select "(Nom) class" from the pull-down menu to tell Weka which attribute you want to predict.
Run IBk for k = 1 to 10 and report the accuracy obtained for each one.
With 10-fold cross-validation, how large is the training set for each run? What accuracy do you get if you set k to this value, so that all neighbors are used when classifying new items?
(7 points) Now let's see what the decision tree can do. Select "J48" ("Choose" -> "Trees" -> "J48"). Using the default options and 10-fold cross-validation, click "Start." What accuracy is obtained?
By default, pruning is on ("unpruned" is False). Click on the "J48" line, set "unpruned" to True, and run it again. What accuracy do you get?
If you don't use cross-validation, just test on the training set, what is the accuracy rate for J48? How can you explain the difference in these results?
(8 points) Now let's see what an SVM can do. Select "SMO" ("Choose" -> "functions" -> "SMO"). Using the default options and 10-fold cross-validation, click "Start." What accuracy is obtained?
By default, SMO uses a linear kernel ("PolyKernel" with -E 1.0). Therefore, the learned model has weights for each feature, not for each support vector. What are the weights learned for each feature? What is the bias value?
Click on the "SMO" line, click "Choose" next to "kernel", and select "RBFKernel" (gamma (-G) defaults to 0.01). How many support vectors are there? What accuracy do you get? Can you find a different value for gamma that gives a higher accuracy?
What to turn in
Upload this file to CSNS under "Homework 2":
<yourlastname>-hw2.txt(or<yourlastname>-hw2.pdfif you prefer to submit in PDF format)
Extra credit
If you wish to tackle some extra credit, you may do so here. You can earn up to 5 points to be applied to any of your homework assignments (but not to exceed 100 on any assignment). To receive these points, you must get at least a 70% on the main part of Homework 2, so finish the regular assignment before moving on to this part.
A) 5 points: Do some research and find out: what is the different
between the ID3 and C4.5 decision trees? What criterion do they use
for picking a feature to split on? What else about these algorithms
differs from our dicussion of decision trees in lecture? Use your
own words; do not copy/paste quotes unless you put them in quotation
marks and attribute them to their author. Put your answers in
<yourlastname-dectrees.txt.
What to turn in
Upload this file to CSNS under "Homework 2: Extra Credit":
<yourlastname>-dectrees.txt(or PDF)